• 18. Regression Summary

Links to: Summary. Chatbot tutor. Questions. Glossary. R functions. More resources.
Regression summary (#regression_summary_chapter-summary).
A linear regression is a linear model that describes a numeric response variable as a function of a numeric explanatory variable. It estimates two parameters: the intercept, \(a\), and the slope, \(b\). Together with an individual’s value for the explanatory variable, \(X_i\), these parameters give the model’s expected value for that individual’s response: \(\hat{Y_i} = a + bX_i\). The difference between what we observed and what the model predicted is called the residual.
The slope tells us how much we expect \(Y\) to change for a one-unit increase in \(X\). Correlation answers a slightly different question: how tightly do \(X\) and \(Y\) move together along a straight-line trend? This chapter works through these ideas, shows how to fit linear regressions in R, and, how to interpret regression results.
Chatbot tutor
Practice Questions
Try these questions! By using the R environment you can work without leaving this “book”. I even pre-loaded all the packages you need!
Setup
I got to wondering how reliably the observed number of pollinator visits that we observe for a RIL predicts the proportion of hybrid seed it sets. So I had a look. I will present these results for different subsets of the data below. I keep these subsets vague and unlabeled to better focus our stats skills.
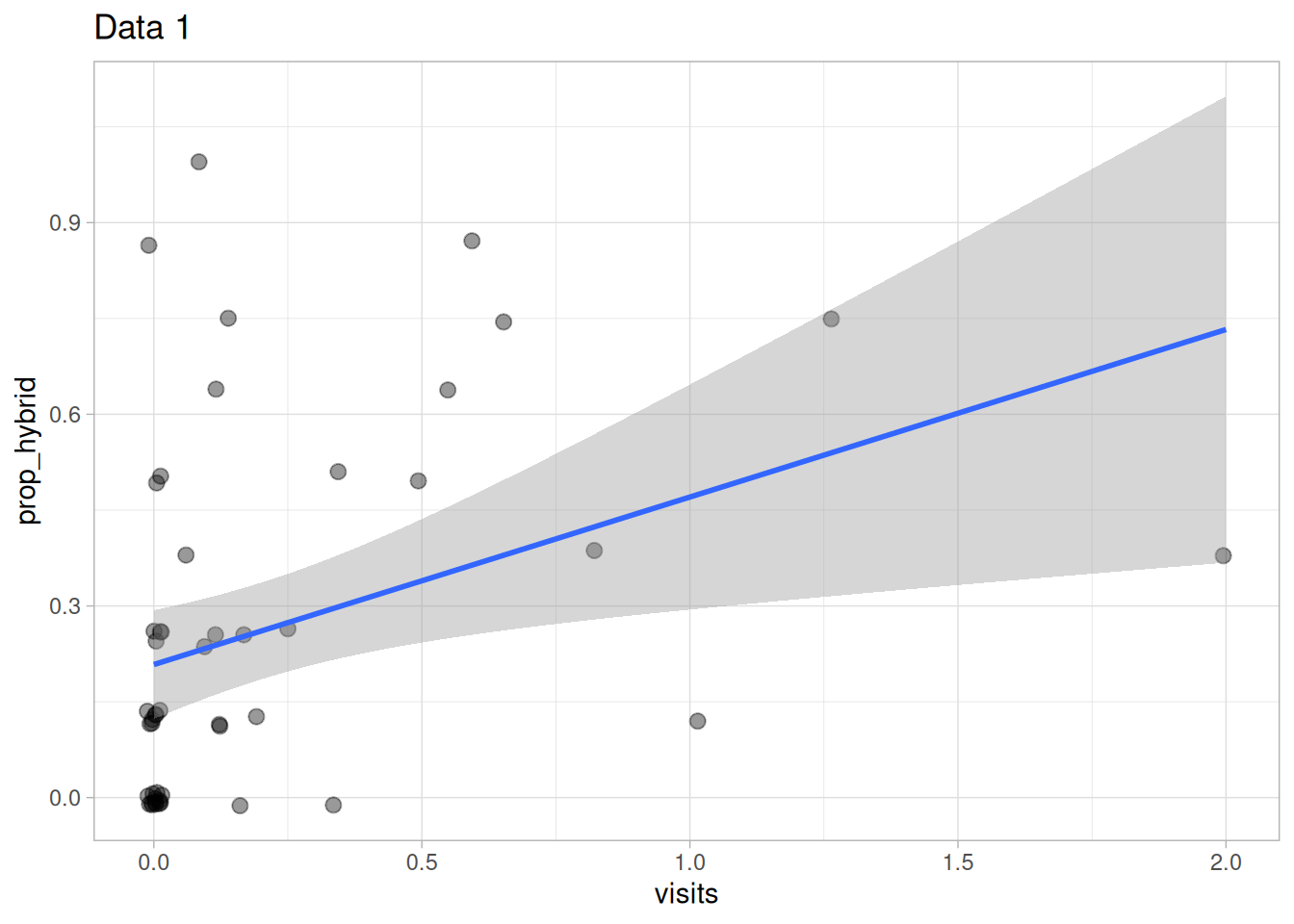
Q1) The grey band in the Figure 2 is a 95% ____ interval.
Q2) This grey band means ___.Q3) Visually estimate the intercept from Figure 2.
Q4) Visually estimate the slope from Figure 2.
Data summary
These data come from a sample of size 49. The covariance between pollinator visits and proportion hybrid seed is 0.039. The means, variances, and standard deviations are:
| variable | mean | var | sd |
|---|---|---|---|
| prop_hybrid | 0.260 | 0.078 | 0.280 |
| visits | 0.197 | 0.149 | 0.386 |
Q5) We expect an additional pollinator visit per observation time to increase the proportion hybrid seeds by ___ .
This question is asking about the slope – \(b = cov_{xy}/var(x)\).
#covariance / var_x
0.039 / 0.149[1] 0.261745Q6) After putting visits and hybrid seed on the same scale, the strength of their linear association is closest to ___.
This question is asking about the correlation – \(r = \frac{cov_{xy}}{s_xs_y}\).
#covariance / (sd_x * sd_y)
0.039 / (0.386 * 0.280)[1] 0.3608438| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | 0.208 | 0.042 | 4.92 | 1.1e-05 |
Q7) We find the intercept of 0.208. The associated p-value is very small (10^{-5}). Why do not we care about this p-value?
Q8) Imagine we observed a RIL that received half a visit (on average) per an observation session. Predict its proportion hybrid seeds (include four places past the decimal, or type NO if you are not comfortable making a prediction).
# Intercept + slope * x_i
0.208 + 0.2617 * .5[1] 0.33885Q9) Imagine we observed a RIL that three visits (on average) per an observation session. Predict its proportion hybrid seeds (include four places past the decimal, or type NO if you are not comfortable making a prediction).
Do not predict out of range!
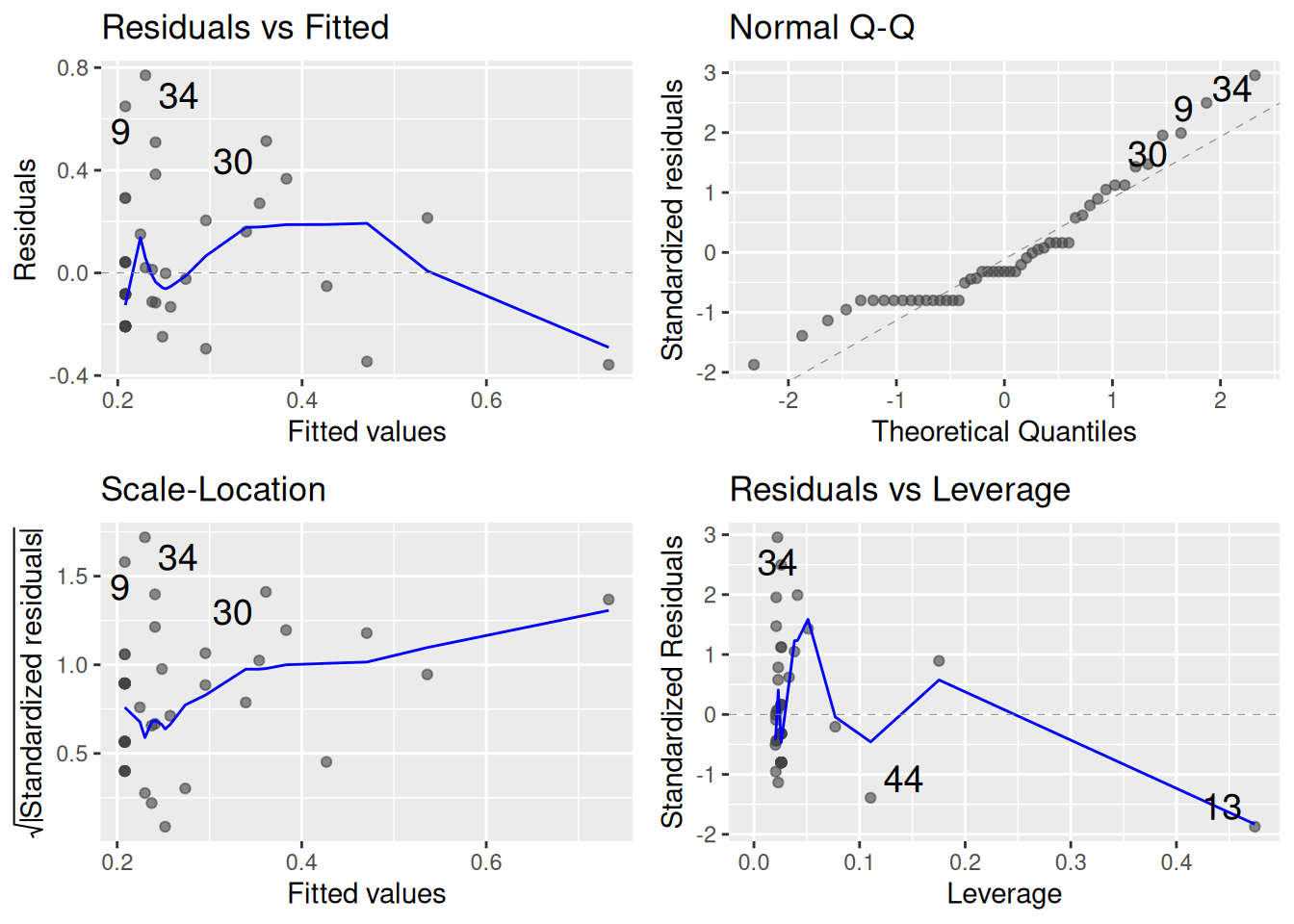
Q10) Consider Figure 3. Which assumption(s) of linear regression seems like the biggest problem here?
Q11) How would you move forward?
Q12) Consider Figure 3. Which data point is the greatest outlier? Refer to it by its number.
Q13) Consider Figure 3. Which data point has the most influence? Refer to it by its number.
Q14) How would you see if influential points are undermining your conclusions?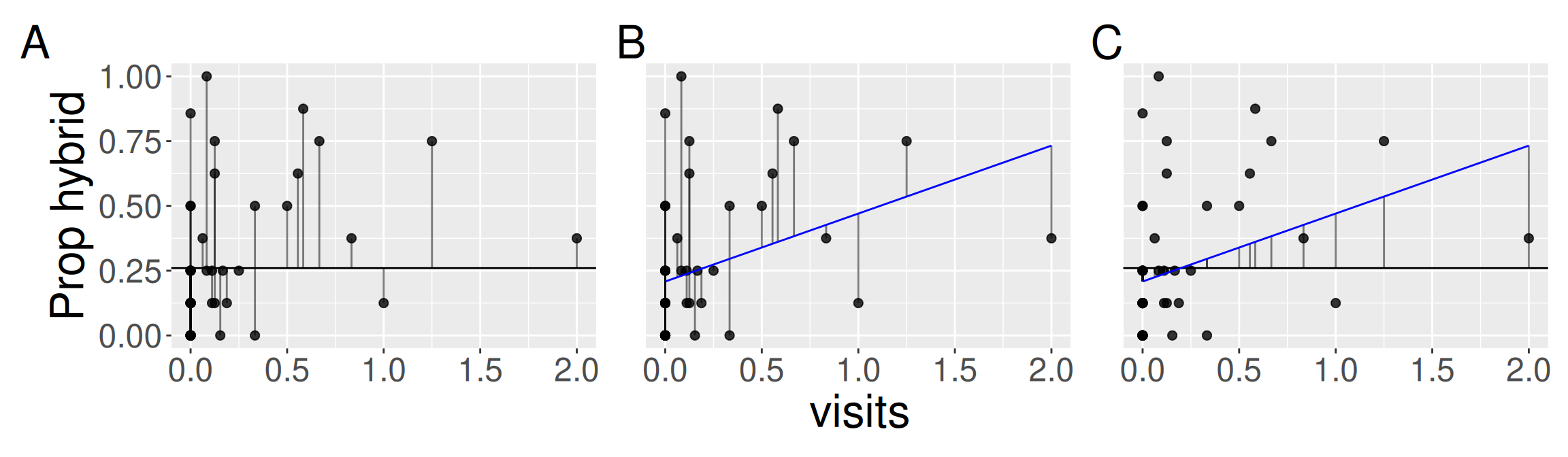
Q15) Which panel in Figure 4 shows the model deviation?
Q16) Which panel in Figure 4 shows the total deviation?
Q17) Which panel in Figure 4 shows the residual deviation?
lm(prop_hybrid ~ visits, data1) |>
augment()|>
summarise( ssa = sum((prop_hybrid - .fitted)^2) ,
ssb = sum((.fitted - mean(prop_hybrid))^2),
ssc = sum((prop_hybrid - mean(prop_hybrid))^2))|>
mutate_all(round, digits = 3)# A tibble: 1 × 3
ssa ssb ssc
<dbl> <dbl> <dbl>
1 3.26 0.493 3.76Q18) What does this line of code calculate?
ssa = sum((prop_hybrid - .fitted)^2)
Q19) What does this line of code calculate?
ssb = sum((.fitted - mean(prop_hybrid))^2)
Q20) What does this line of code calculate?
ssc = sum((prop_hybrid - mean(prop_hybrid))^2)
Q21) Which equation summarizes the relationship among these three sums of squares in this linear regression?
Q22) Which equation defines \(R^2\) from the sums of squares in a linear regression?
| ssa | ssb | ssc |
|---|---|---|
| 3.262 | 0.493 | 3.755 |
See which equals the squared correlation coefficient from above.
data1|>
summarise(r = cor(prop_hybrid , visits),
r2 = r^2) # A tibble: 1 × 2
r r2
<dbl> <dbl>
1 0.362 0.131Let’s test the null hypothesis
Q23) The null hypothesis is:
Q24) N = 49. So, the F value is
From above
- SS_model = 0.493.
- SS_error = 3.26.
So …
- MS_model = 0.493/1 = 0.493.
- MS_error = 3.26/47 = 0.069.
- F = 0.493/0.069 = 7.1.
Q25) The p-value is:
From above
pf(7.1,1,47,lower.tail = FALSE)[1] 0.01052926) What do we do to the null hypothesis?
Q27) What does rejecting this null hypothesis mean in this context?📊 Glossary of Terms
Concepts
Linear regression: A linear model that predicts a numeric response variable, \(Y_i\), from an intercept, \(a\), a slope, \(b\), and the value of a numeric explanatory variable, \(X_i\): \(\hat{Y_i} = a + bX_i\).
Slope, \(b\): The expected change in \(Y\) for every one-unit increase in \(X\). In simple linear regression, \(b = \frac{\text{cov}_{xy}}{s^2_x}\).
Intercept, \(a\): The predicted value of \(Y\) when \(X = 0\). This prediction is not always biologically or scientifically meaningful. Often, the intercept is simply the anchor needed to place the regression line correctly. The intercept is \(a = \bar{Y} - b\bar{X}\).
Correlation, \(r\): A standardized summary of the strength and direction of a linear association between two numeric variables. Correlation ranges from -1 to 1 and is unitless, so it is easier to compare across variables measured on different scales.
Covariance: A summary of the extent to which two variables vary together. Covariance is positive when high values of \(X\) tend to occur with high values of \(Y\), negative when high values of \(X\) tend to occur with low values of \(Y\), and near zero when there is little linear association.
Fitted value, \(\hat{Y_i}\): The value predicted by the regression model for observation \(i\): \(\hat{Y_i} = a + bX_i\).
Residual, \(e_i\): The difference between an observed value and its fitted value: \(e_i = Y_i - \hat{Y_i}\). Residuals tell us how far each observation is from the regression line.
t-based approach to linear regression
Standard error of the slope, \(SE_b\): A measure of uncertainty in the estimated slope. In simple linear regression, \(SE_b = \frac{s_e / s_x}{\sqrt{n - 2}}\), where \(s_e\) is the standard deviation of the residuals and \(s_x\) is the standard deviation of the explanatory variable.
t-statistic for a slope: A test statistic that measures how many standard errors the estimated slope is from the null value of zero: \(t = \frac{b}{SE_b}\).
ANOVA approach to linear regression
Model sum of squares, \(SS_\text{model}\): The amount of variation in \(Y\) explained by the regression model: \(SS_\text{model} = \sum(\hat{Y_i} - \bar{Y})^2\).
Error sum of squares, \(SS_\text{error}\): The amount of variation in \(Y\) left unexplained by the regression model: \(SS_\text{error} = \sum(Y_i - \hat{Y_i})^2 = \sum e_i^2\).
Total sum of squares, \(SS_\text{total}\): The total variation in the response variable around its mean: \(SS_\text{total} = \sum(Y_i - \bar{Y})^2\).
Proportion of variance explained, \(R^2\): The proportion of total variation in \(Y\) explained by the regression model: \(R^2 = \frac{SS_\text{model}}{SS_\text{total}}\). In simple linear regression, \(R^2 = r^2\).
Assumptions & how to evaluate them
Linearity: The assumption that the expected value of the response variable can be reasonably modeled as a straight-line function of the explanatory variable.
Homoscedasticity: The assumption that the residuals have roughly equal variance across the range of fitted values or explanatory-variable values.
Normality of residuals: The assumption that residuals are approximately normally distributed. This matters most for standard errors, confidence intervals, and p-values based on the t- and F-distributions.
Diagnostic plots: Plots used to evaluate whether a linear model is a reasonable summary of the data. Common diagnostic plots include residuals vs. fitted values, Q-Q plots, scale-location plots, and residuals vs. leverage plots.
Leverage: A measure of how unusual an observation is in its explanatory-variable value. Points with high leverage have the potential to strongly affect the fitted regression line.
Influence: A measure of how much a fitted model would change if a particular observation were removed. Cook’s distance is a common measure of influence.
Prediction caveats
Extrapolation: Using a regression model to make predictions outside the range of the data used to fit the model. Extrapolated predictions can be unreliable, even when the model fits the observed data well.
Prediction out of context: Using a regression model in a biological or experimental context different from the one in which the data were collected. This can be risky even when the new values of \(X\) are within the original range.
Attenuation: The weakening of an estimated association caused by measurement error. In regression, measurement error in the explanatory variable can make the estimated slope and correlation smaller than the true relationship.
💻 Key R Functions
Plotting regression relationships
geom_smooth(method = "lm"): Adds a fitted linear regression line to a plot. The shaded region shows uncertainty in the fitted mean trend unlessse = FALSE.
Fitting and summarizing linear models
lm(): Fits a linear model. For simple linear regression, uselm(y ~ x, data = my_data).coef(): Extracts model coefficients from a fitted model. For simple linear regression, these are the intercept and slope.summary(): Gives a detailed base R summary of a fitted model, including estimates, standard errors, t-statistics, p-values, residual summaries, and \(R^2\).confint(): Calculates confidence intervals for model parameters, such as the intercept and slope.anova(): Produces an ANOVA table for a fitted linear model, partitioning variation into model and error sums of squares.
Working with model output
broom::tidy(): Converts model output into a tidy table with one row per model term. Useful for extracting estimates, standard errors, test statistics, p-values, and confidence intervals.broom::augment(): Adds model information back to the original data, including fitted values, residuals, standardized residuals, leverage, and Cook’s distance.broom::glance(): Produces a one-row summary of a model, including values such as \(R^2\), adjusted \(R^2\), the F-statistic, and model-level p-values.
Model diagnostics
plot(): When applied to anlmobject, produces standard diagnostic plots for evaluating linear model assumptions.
Summaries of association
cor(): Calculates the correlation between two numeric variables.cov(): Calculates the covariance between two numeric variables.var(): Calculates the variance of a numeric variable. In simple linear regression, the slope can be calculated as covariance divided by the variance of \(X\).sd(): Calculates the standard deviation of a numeric variable. Used in formulas for standard errors and Z-transformations.
Additional resources
Videos:
Simple Linear Regression, a video introduction to fitting and interpreting a regression line.
Interactive resources:
Least-Squares Regression, from PhET Interactive Simulations. Drag points around and watch how the fitted line, residuals, and least-squares criterion change.
Readings:
Inference for linear regression with a single predictor, from OpenIntro. This is a useful follow-up for reviewing confidence intervals, hypothesis tests, and assumptions for simple linear regression.
Basic Regression, from ModernDive. This chapter gives a tidyverse-friendly introduction to regression using
ggplot2,lm(), and model interpretation.Regression II: Linear Regression, from Data Science: A First Introduction. This chapter frames regression as a prediction tool and discusses model fit, outliers, and interpretation.
Simple Linear Regression, from A Handy Workbook for Research Methods & Statistics. This is a hands-on R-based walk-through of fitting and interpreting simple linear models.
Multiple Linear Regression Model, from Keller Biostat. This resource looks ahead to regression models with more than one explanatory variable.
Cautionary tales:
- Statistical cognition in the media, from Language Log. A useful example of why statistical claims in public writing need careful interpretation.