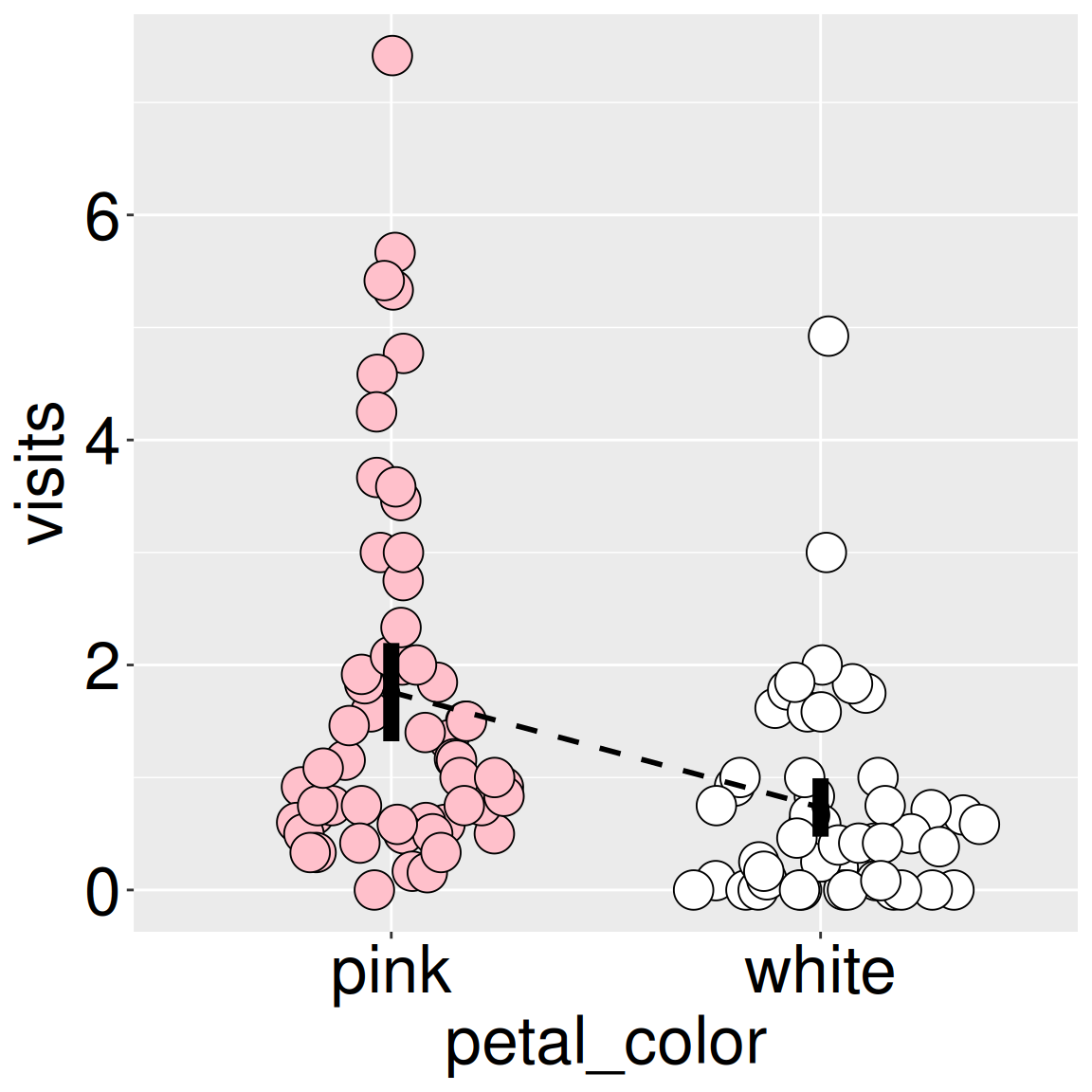
Figure 1: Each point shows an individual RIL’s mean pollinator visits. Vertical lines95% confidence intervals for each flower color. The dashed line connects the group means to facilitate comparison.
Here’s a brief refresher of our previously introduced standard summaries of associations between a categorical explanatory variable and a continuous response.
Remember that even though data do not fully meet assumptions (we can even see the right skew in the sina plot - Figure 1). Recall that if data meet assumptions of our parametric model, we can reasonably trust the results of our analysis. If data do not meet assumptions of the parametric model, results may or may not be valid, depending on how robust the test is. We will therefore conduct a permutation test and a bootstrap later to see if our t-test was trustworthy.
Estimating summaries of each group:
We can summarize within group means, and variances (or even 95% CIs, if we want) as we saw in the previous chapter. I present some of these high-level summaries in Figure 1 and calculate them below:
We would also like to summarize the two groups jointly by estimating the pooled variance, the difference in group means, and a standardized version of that difference.
The pooled variance: To estimate both the effect size as Cohen’s D and uncertainty, we need to calculate the variance. But we have two groups, so we need something like “the average variance within each group.” The pooled variance, \(s^2_p\) – the variance in each group weighted by their degrees of freedom and divided by the total degrees of freedom, is this average (see margin for hand calculation).
The difference in means: To find this, simply subtract one mean from the other: \(\text{mean}\_\text{diff}= 1.76 - 0.733 = 1.03\).
Cohen’s D as the difference in means standardized by the pooled standard deviation. Cohen’s D \(=\frac{\text{mean diff}}{s_p}\)\(=\frac{1.03}{\sqrt{1.833}}\)\(=\frac{1.03}{1.35}\)\(= 0.76\). This is considered a medium (borderline large) effect, so it likely matters (if true).
We can calculate these global summaries from the caculations of each petal color (above):
The cohens_d() function in the effectsize package will calculate Cohen’s D for you! It even provides a 95% confidence interval for this estimated effect size. This package includes additional summaries of the effect size in a two-sample analysis depending on modeling assumptions. Read more here.
# Not working? Install the effectsize package!library(effectsize) cohens_d(visits ~ petal_color, data = SR_visits )
Cohen's d | 95% CI
------------------------
0.76 | [0.36, 1.15]
- Estimated using pooled SD.