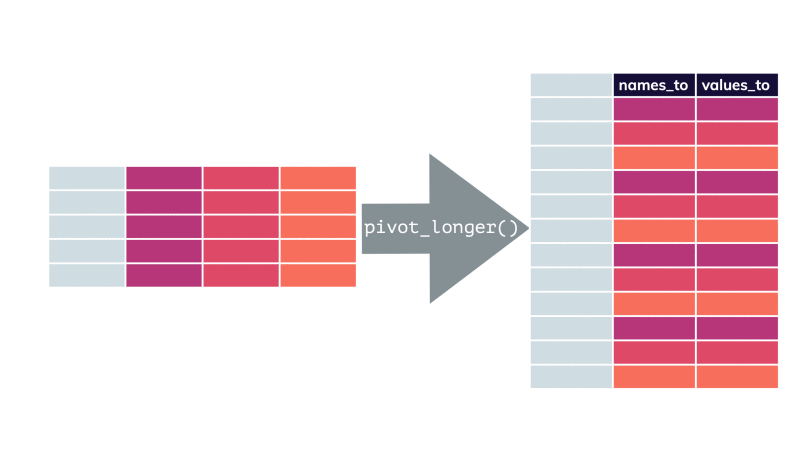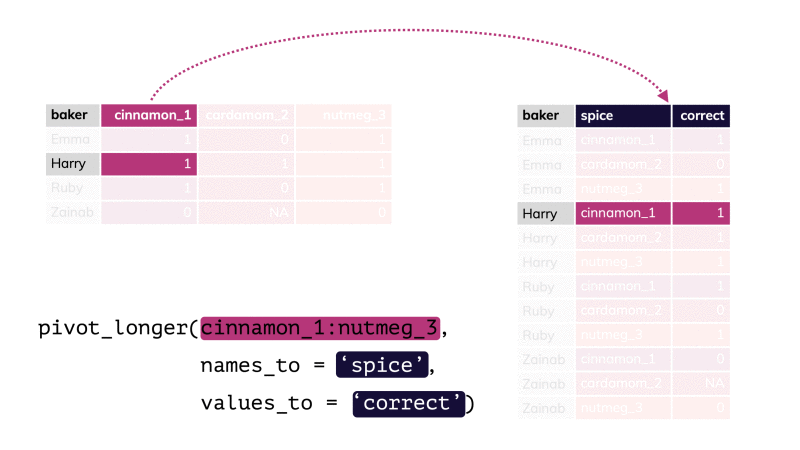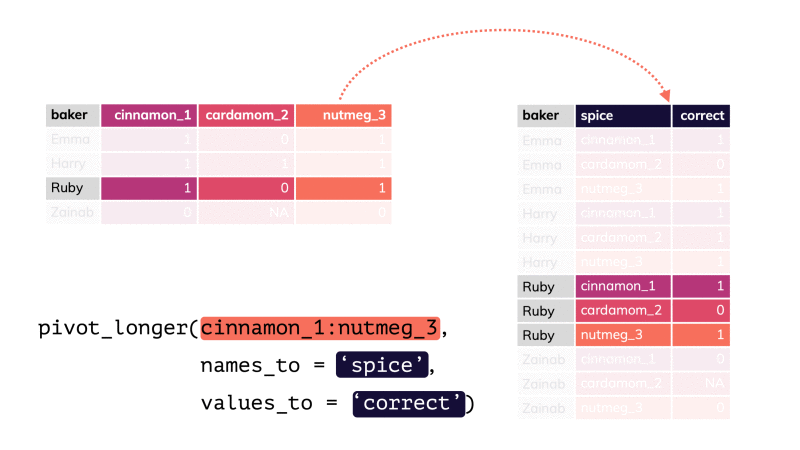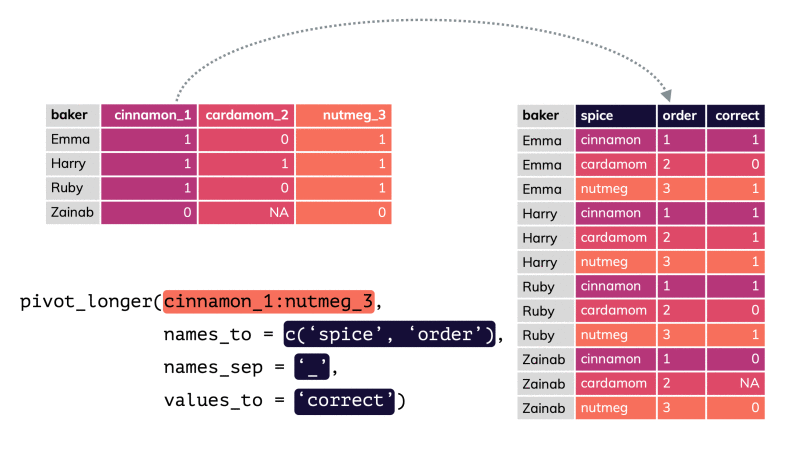
Rows: 593
Columns: 17
$ ril <chr> "A1", "A100", "A102", "A104", "A106", "A107", "A10…
$ location <chr> "GC", "GC", "GC", "GC", "GC", "GC", "GC", "GC", "G…
$ prop_hybrid <dbl> 0.000, 0.125, 0.250, 0.000, 0.000, 0.125, NA, 0.00…
$ mean_visits <dbl> 0.0000, 0.1875, 0.2500, 0.0000, 0.0000, 0.0000, NA…
$ growth_rate <chr> "1.272", "1.448", "1.8O", "0.816", "0.728", "1.764…
$ petal_color <chr> "white", "pink", "pink", "white", "white", "pink",…
$ petal_area_mm <dbl> 43.95220, 55.78633, 51.70312, 57.28095, 68.55464, …
$ date_first_flw <dbl> 95.38681, 96.75742, 97.95671, 95.21548, 96.75742, …
$ node_first_flw <dbl> 20.51416, 25.26508, 24.91316, 15.58727, 18.40264, …
$ petal_perim_mm <dbl> 43.07237, 43.84228, 47.29937, 47.01340, 55.71933, …
$ asd_mm <dbl> 0.4466794, 1.0730412, 0.6744473, 0.9591572, 1.4146…
$ protandry <dbl> 1.2812553, 1.1107347, 0.9402142, 1.2812553, 2.8159…
$ stem_dia_mm <dbl> 1.924, 2.328, 2.422, 1.826, 1.890, 1.954, 2.120, 1…
$ lwc <dbl> 0.8311, 0.8376, 0.8421, 0.8236, 0.8249, 0.8316, 0.…
$ crossDir <chr> "A", "A", "A", "A", "A", "A", NA, "A", "A", "A", "…
$ num_hybrid <dbl> 0, 1, 2, 0, 0, 1, NA, 0, 0, 2, 0, NA, NA, 1, 0, NA…
$ offspring_genotyped <dbl> 8, 8, 8, 8, 8, 8, NA, 8, 8, 8, 8, NA, NA, 8, 8, NA…